DEMYSTIFYING DATA PRODUCTS: A DATA GAME CHANGER YOU CAN’T IGNORE
The world of data management is undergoing a transformation. While some traditional methods had limitations, the concept of data mesh is paving the way for a more effective approach. In this article, we dive into the concept of data products, a important element of the data mesh approach and we explore its key characteristics.
What are They & What makes Them Different?
Here are some real-world examples:
- A customer 360 that unifies data from sales, marketing, and customer service departments.
- A pre-built report with a user-friendly interface for sales & marketing teams to analyze customer trends.
- A machine learning model for predicting customer churn, embedded within a CRM platform.
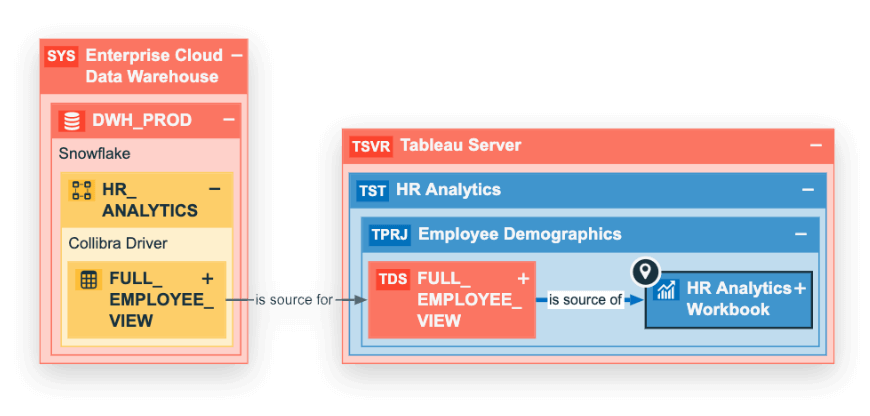
They go beyond just delivering raw data and focus on the entire data lifecycle, from understanding the user needs to ensuring proper data quality and security. Traditional data management focused primarily on the technical aspects of data creation and delivery. Data products on the other hand, emphasize the user experience and business value of data, adopting a “product thinking” mentality.
Key Characteristics

Building meaninful products requires a data team with diverse expertise. Next to the expertise, here are some essential characteristics to consider:
- Discoverability & Data Collection: Users should be able to easily find and understand available data products. Data registries with detailed descriptions and metadata are crucial.
- Observability: Data is constantly changing. They should be equipped with tools to detect and address anomalies promptly, ensuring ongoing reliability.
- Quality: Trustworthy data is paramount. They should leverage robust quality control measures to ensure accurate and reliable information.
- Consumability: Making your data consumable & insightful in an easy and flexible way is key. This doesn’t only apply on the development but also the presentation.
- Security: Data security is especially important in a self-service analytics environment. Access controls and adherence to data privacy regulations are vital.
- Process: Streamlining the data product development process is key. DataOps practices, including automation and continuous integration & improvement, can accelerate delivery.
Benefits
By implementing data products, organizations can expect several advantages:
- Increased data utilization: Discoverable and user-friendly data products encourage broader data consumption.
- Improved decision-making: Data-driven insights empower businesses to make informed choices.
- Enhanced agility: Faster development and deployment of data products lead to quicker adaptation.
- Potential for monetization: Certain data products can be valuable assets for external use.
Conclusion
Data products are revolutionizing data management by transforming data into readily consumable information. By focusing on user needs, quality, and operational efficiency, companies can leverage them to unlock new levels of business success. If your organization is looking to gain a competitive edge through data-driven decision-making, then embracing this approach is a powerful step forward.