DECODING YOUR DATA LANDSCAPE: UNDERSTANDING BUSINESS AND TECHNICAL DATA ARCHITECTURE FOR EFFECTIVE DATA GOVERNANCE
In today’s data-driven world, organizations are increasingly recognizing the immense value hidden within their data. However, simply collecting data isn’t enough. To truly unlock its potential, businesses need a well-defined data architecture supported by robust data governance. This article explores the critical distinction between business data architecture and technical data architecture, the two pillars of data architecture, and how data governance serves as the bridge between them to deliver meaningful business outcomes.

Business Data Architecture: Laying the Foundation with Business Needs
Business data architecture serves as the strategic blueprint for your organization’s data from a business perspective. It addresses what data you need and why, connecting this data to business goals and processes. It focuses on the meaning and context, emphasizing business semantics rather than technical implementation. The primary audience includes business stakeholders such as business analysts, data owners, subject matter experts, and leaders who understand core business requirements and how data supports strategic objectives.
At its heart, business data architecture creates conceptual and logical data models that represent key business entities (customers, products, orders), their attributes, and relationships, all described in business terms. For instance, a business data architect might define “Customer” as an entity with attributes like “Customer Name,” “Contact Information,” and “Purchase History,” and establish relationships with entities like “Order” and “Product.”
Key Functions of Business Data Architecture
Business data architecture identifies and defines core entities, establishing a common organizational understanding of key data elements. It maps relationships between data elements, showing how different pieces connect from a business perspective. The architecture determines data quality requirements, establishing necessary levels of accuracy, completeness, and consistency for various business processes. It analyzes how data supports business decisions through reporting, analytics, and strategic planning. Furthermore, it defines ownership and governance policies, assigning responsibility for data accuracy and integrity while outlining rules for access and usage.
Deliverables of Business Data Architecture
The outputs of business data architecture include conceptual data models illustrating the main entities and relationships from a business perspective. More detailed logical data models define attributes, data types, and relationships in a technology-independent manner. Business glossaries and data dictionaries provide comprehensive terminology definitions, ensuring consistent language across the organization. High-level data flow diagrams show how information moves through key business processes, while data governance frameworks outline the policies, procedures, and responsibilities for data management.
Ultimately, business data architecture provides the “why” behind the data, ensuring alignment between data strategy and business strategy, so that collected and managed data truly serves organizational needs.
Technical Data Architecture: Bringing the Blueprint to Life
Technical data architecture deals with the practical implementation and management of data using specific technologies and systems. It translates the business blueprint into concrete plans for how data will be stored, processed, secured, and made accessible. The primary audience includes technical stakeholders such as data engineers, database administrators, system architects, and IT professionals responsible for designing, building, and maintaining the data infrastructure.
Key Functions of Technical Data Architecture
Technical data architecture involves selecting appropriate storage systems by choosing the right types of databases, warehouses, and storage technologies based on specific requirements and performance needs. It includes physical database design, creating schemas, tables, columns, indexes, and other objects optimized for efficiency. The architecture implements integration mechanisms, building ETL/ELT processes and data pipelines to move and transform data between systems. It develops security protocols with access controls, encryption methods, and protection measures against unauthorized access. Performance optimization ensures system responsiveness and efficiency, while data lineage tracking monitors how information flows through various systems.
Deliverables of Technical Data Architecture
The concrete outputs include physical data models and database schemas that define the actual implementation of data structures. Integration pipelines show how data moves between systems, while security architectures detail protection mechanisms. Data warehouse and lake designs provide blueprints for analytical environments, accompanied by performance optimization plans to ensure system efficiency. Together, these elements create the technical foundation that supports business data needs.
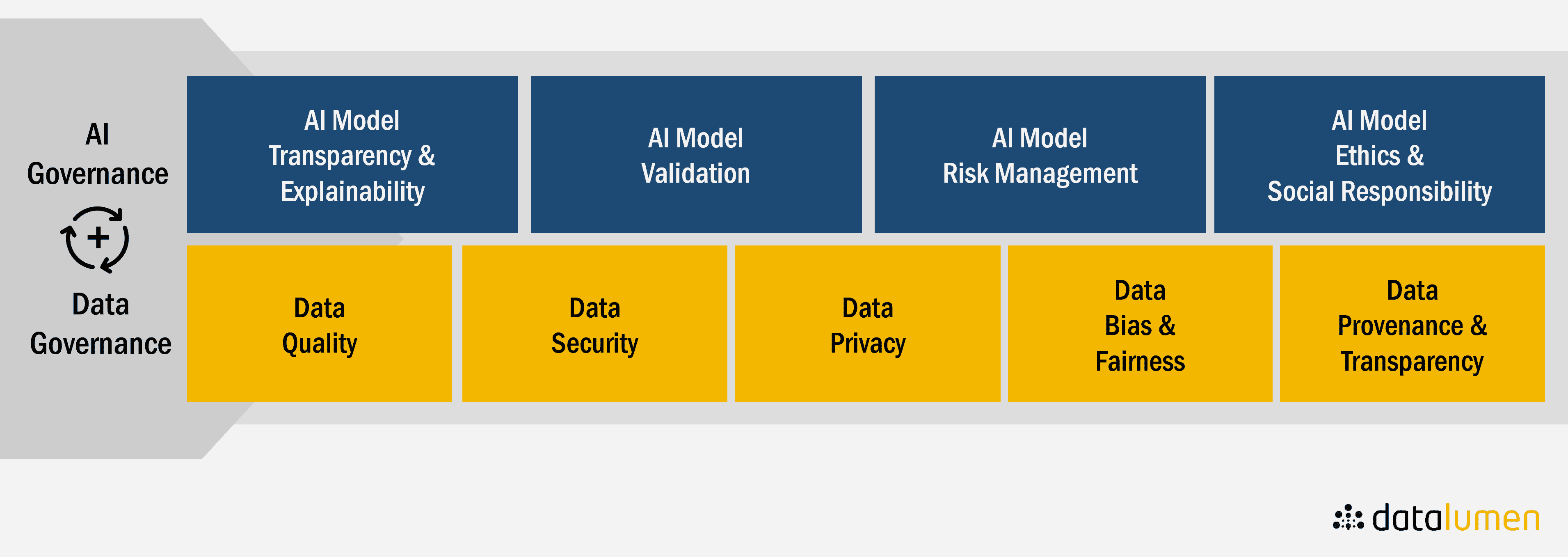
The Bridge: Data Governance as the Crucial Connector
The Critical Interplay Between Business and Technology
Business and technical data architecture must work in harmony for effective data management. Business architecture defines the “what” and “why” of data needs, while technical architecture determines the “how” of implementation. Imagine trying to build a house without an architect’s blueprint – the construction team wouldn’t know what to build or how the different parts should fit together. Similarly, a strong technical data architecture without a solid understanding of business needs risks building a system that doesn’t actually solve the right problems or deliver the required value.
Data Governance: The Framework for Success
Data Governance (DG) serves as the essential bridge between business and IT, ensuring that the data landscape is managed effectively to enable strategic execution. DG guarantees that business and technical architectures remain aligned through clear communication channels and shared understanding. It also ensures that data assets deliver measurable business value through proper management, quality control, and strategic utilization.
Key Principles for Effective Data Governance
Effective data governance focuses primarily on behavior change and communication improvement rather than simply deploying technological tools. Organizations should position data governance as a fundamental business function, similar to finance or compliance, with clear responsibilities and accountability. Communication about data governance should emphasize business outcomes such as return on investment and risk mitigation, rather than focusing solely on policies and procedures.
A critical aspect involves clearly separating yet connecting business data architecture and technical data architecture, acknowledging their distinct roles while ensuring they work together seamlessly. Data governance must facilitate ongoing collaboration between business and technical teams, creating forums for regular communication, joint problem-solving, and shared decision-making regarding data assets.
Conclusion: Creating a Cohesive Data Strategy
By recognizing the distinct roles of business and technical data architecture, and implementing a robust data governance framework to bridge them, organizations can build an effective data landscape that drives business value.
This comprehensive approach ensures that business needs drive technical implementation while technical capabilities inform business possibilities. Data governance provides the structure for sustainable success, guiding the organization’s data journey through changing business requirements and evolving technologies.
In the data-driven era, this integrated strategy is essential for organizations seeking to transform data from a resource into a true strategic asset. The clear delineation between business and technical data architecture, connected through thoughtful data governance practices, creates the foundation for data-driven decision making, operational excellence, and strategic advantage in an increasingly competitive landscape.