
FISHING FOR BETTER BIG DATA INSIGHTS WITH AN INTELLIGENT DATA LAKE
Fishing in a lake and a data lake are much the same.
Data scientists must not only go where the fish are for big data insights, but also find a way to quickly build the data pipeline that turns raw data into business results.
When fishing it doesn’t matter how good of a fisherman you are—you’re not going to catch anything if you’re not fishing where the fish are. This same bit of advice extends to data lakes.
Not even the best data scientists in the world can find insights in data lakes that are nothing but data swamps. But that’s what most data analysts are using today—swamps filled with databases, file systems, and Hadoop clusters containing vast amounts of siloed data, but no efficient way to find, prepare, and analyze that data. That is why ideally you have collaborative self-service data preparation capabilities with governance and security controls.
With this in mind, Informatica launched Big Data Management, which included a Live Data Map component to collect, store, and manage the metadata of many types of big data and deliver universal metadata services to power intelligent data solutions, such as the Intelligent Data Lake and Secure@Source. Intelligent Data Lake leverages the universal metadata services of Live Data Map to provide semantic and faceted search and a 360-degree-view of data assets such as end-to-end data lineage and relationships.
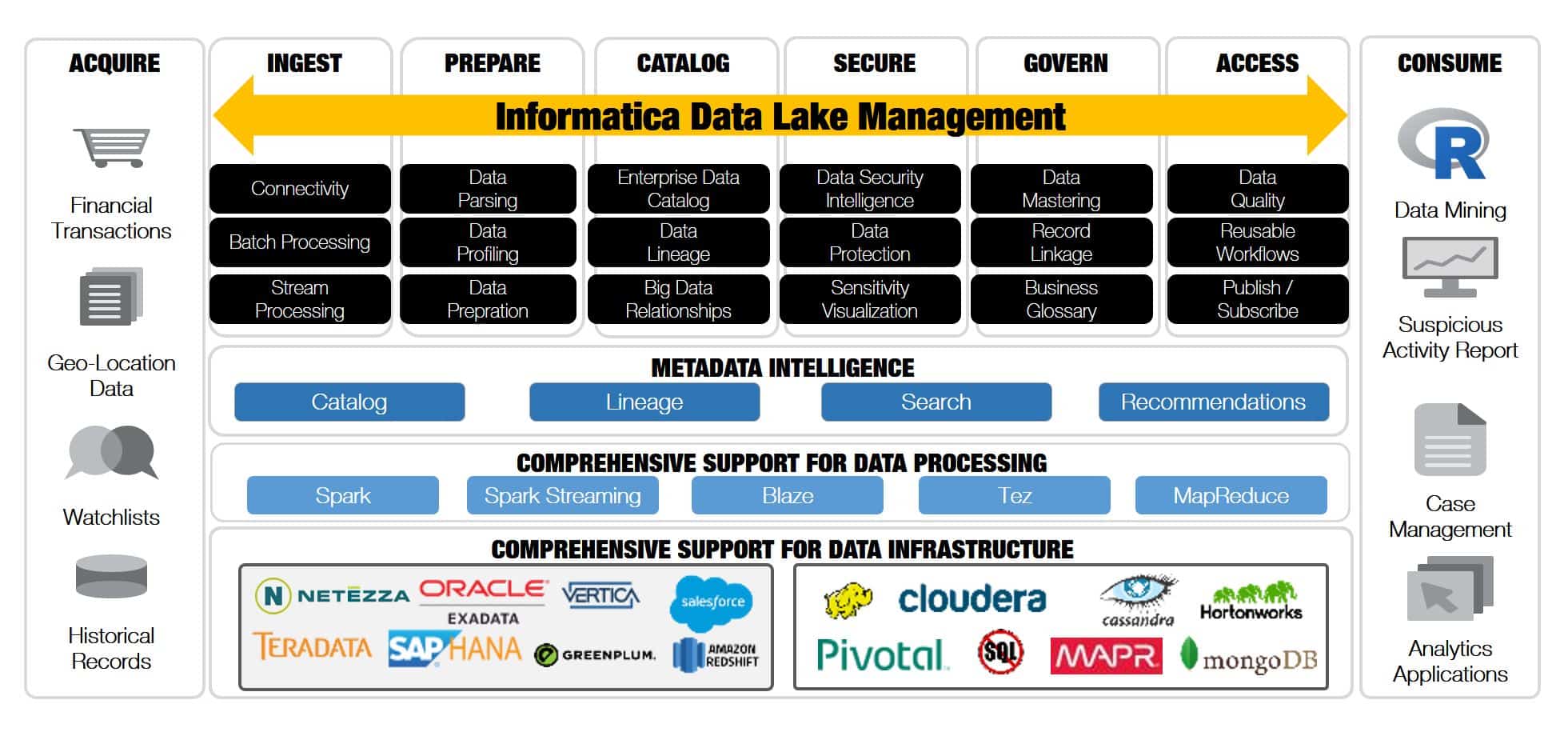
In addition to smart search and a 360-degree-view of your data, Intelligent Data Lake provides analysts with a project workspace, schema-on-read data preparation tools, data profiling, automated data discovery, user annotation and tagging, and data set recommendations based on user behavior using machine learning. These capabilities make it much easier for analysts to “fish where the fish are” for big data insights.
In order to “land the fish” and turn these insights into big value, there needs to be a way to quickly build the data pipeline that turns raw data into business results. Intelligent Data Lake does this automatically by recording all the actions of a data analyst as they prepare data assets in what is called a “recipe.” These recipes then generate data pipelines (called mappings in Informatica) that IT can automatically deploy into production. What better way to turn insights into business value and fry up those fish you just caught?
If you want to see how an Intelligent Data Lake works through a live demo, please contact us or have a chat with us at the upcoming Big Data & Analytics 2017 event.



